Optimizing Metal: Stitch several Metal functions into a single shader using MTLFunctionStitchingGraph
In this post I’ll show how to use Metal’s new feature MTLFunctionStitchingGraph to create an image processing pipeline in a single shader instead of chain of several GPU kernels. In terms of common GPU practices it is a new option for creating uber-shaders in runtime using precompiled Metal functions. And for large pipelines it can be much more efficient than compiling the whole shader from source in runtime and less error prone.
With this post I start a new series of articles about Metal optimizations. I’ll cover several topics which I found interesting and useful for Metal pipeline creation and encoding which can help you to process your pipelines faster. And I’ll try to explain them in details so that you can use them in your projects.
This technology is used inside Apple’s MPSGraph but MPSGraph doesn’t allow to inject custom shaders in it and works only with multidimensional arrays. I’ll show how to create MPSGraph like processing but with plain old Metal textures and of course your own shaders.
What is MTLStitchingGraph?
In most cases a single shader will be more efficient comparing to several shaders chained together. A long time ago Apple introduced function constants which is a good alternative to preprocessing macros which can remove unnecessary branching from shader code during processing. Metal Stitching Graph is another option to create uber-shaders in runtime. And it can be much more flexible. You’re not stuck to a single shader with compile time branching but can create shader from building blocks right in runtime. I’ll show how to do it for image processing but this API can be used in processing all kinds of data on GPU.
Usually if you want to create node based GPU processing engine you define several types of nodes and allow user or some external API (for example JSON encoded graph received from server) define the order of nodes execution. Each node in this architecture represents atomic processing task. For example one node applies blur filter to input texture, another one adjusts texture brightness and so on.
This is a very flexible architecture but it has some drawbacks. First of all each node will be encoded to separate shader and GPU will perform full texture processing for each of them. Second you need to create a separate output texture in memory to store the result of node processing which will be provided as input to the next node. And last but not least the full graph processing will be encoded on each call. For example you have a graph with 10 nodes and user adjusts brightness (one parameter for one node) the full pipeline will be encoded again. With MTLStitchingGraph you can avoid all of these drawbacks. But it will require to completely rethink your node engine architecture.
MTLFunctionStitchingGraph allows you to create a Metal function or several functions in runtime which will be executed for each pixel (or any data) and have all the processing steps defined by your graph. Actually it is just an API for creating directed acyclic graphs which will be executed on GPU. Good example of it is MPSGraph, Apple framework for neural network training and inference on GPU.
Stitchable Function
In the heart of Metal Stitching Graph is a [[ stitchable ]] Metal function which is a new function qualifier like [[ kernel ]], [[ vertex ]] or [[ fragment ]]. And the only purpose of this type of function is to be stitched with other functions to create a chain of executions on GPU inside a single function. Let’s try to build a simple graph which will apply grayscale filter to input image and then invert its color.
#include <metal_stdlib>
using namespace metal;
[[ stitchable ]]
half4 read_color(const texture2d<half, access::read> tex,
const ushort2 position) {
return tex.read(position);
}
[[ stitchable ]]
void write_color(const texture2d<half, access::write> tex,
const half4 color,
const ushort2 position) {
tex.write(color, position);
}
[[ stitchable ]]
half4 grayscale_color(const half4 color) {
return half4(half3((color.r + color.b + color.g) / 3.0h), color.a);
}
[[ stitchable ]]
half4 invert_color(const half4 color) {
return half4(half3(1.0h - color.rgb), color.a);
}This is our Metal file which will be compiled to Metal library during Xcode build. It contains four [[ stitchable ]] functions. First two functions are used to read color from texture and write color. The last two functions are actual image processing functions. They are very simple and don’t do any complex processing. But they are enough to show how to use MTLFunctionStitchingGraph.
In regular image processing pipeline you will define two separate [[ kernel ]] functions each of which will receive source texture to read from and destination texture to write to. So on CPU side you’ll create input texture, separate texture to store grayscale result and another one to store inverted result which will be the output of your pipeline.
With Metal Stitching Graph you don’t need an intermediate texture to store grayscale result because both functions will be executed in a single shader one after another like if you wrote a separate [[ kernel ]] function for grayscale_and_invert.
Stitching Graph
Let’s create a graph which will execute these two functions in a single shader. We will do it in four separate steps which I’ll explain in details.
- Create graph description with all the nodes and connections between them;
- Compile graph to a separate Metal library with a single function which will execute our graph;
- Create another Metal library from source with a single
[[ kernel ]]function which will be used to execute our graph; - Create pipeline state with this shiny new kernel.
After this you can encode this kernel as any other kernel function, add it to a larger pipeline or use it as a standalone function. I’ll show how to do it in Swift but since all of the Metal API is available in Objective-C you can use it in your Objective-C projects as well or C++ projects with Metal-C++ header library or Objective-C++ wrapper.
Graph Description
let inputs: [MTLFunctionStitchingInputNode] = [
MTLFunctionStitchingInputNode(argumentIndex: 0), // source texture
MTLFunctionStitchingInputNode(argumentIndex: 1), // destination texture
MTLFunctionStitchingInputNode(argumentIndex: 2), // pixel position
]
let readColor = MTLFunctionStitchingFunctionNode(
name: "read_color",
arguments: [inputs[0], inputs[2]],
controlDependencies: []
)
let grayscaleColor = MTLFunctionStitchingFunctionNode(
name: "grayscale_color",
arguments: [readColor],
controlDependencies: []
)
let invertColor = MTLFunctionStitchingFunctionNode(
name: "invert_color",
arguments: [grayscaleColor],
controlDependencies: []
)
let writeColor = MTLFunctionStitchingFunctionNode(
name: "write_color",
arguments: [inputs[1], invertColor, inputs[2]],
controlDependencies: []
)
let graph = MTLFunctionStitchingGraph(
functionName: "process_graph",
nodes: [
readColor,
grayscaleColor,
invertColor,
writeColor,
],
outputNode: nil,
attributes: []
)Let’s go through this code line by line. First you define inputs for your graph. These are the actual arguments for Metal Shading Language (MSL) [[ visible ]] function which we will later compile to Metal library. Notice that you don’t define types of inputs even though MSL as a C++ based language requires types of arguments to be defined in function declaration. Types of these arguments will be found from the arguments of [[ stitchable ]] functions which later uses these inputs.
Next you define nodes of your graph. Each node is a MTLFunctionStitchingFunctionNode which represents a single [[ stitchable ]] function. You need to provide a name of this function from your Metal library, list of arguments and list of control dependencies.
Arguments of these nodes have to be the other nodes of the graph, so you can’t inject a single float or integer value as an argument which can be a good addition to current API (Apple, please :). You need to create a separate input node for each value you want to pass to your graph using MTLBuffer or if they are of a single type you can put them into a one buffer of course.
Control dependencies define the order of execution. Each directed acyclic graph can be converted into a sequence, such that for every edge the start vertex of the edge occurs earlier in the sequence than the ending vertex of the edge. This operation is called topological ordering and Metal Stitching Graph will do it for us. Graph can have several such orderings but will have at least one. For example a simple graph from this article cover has six orderings.
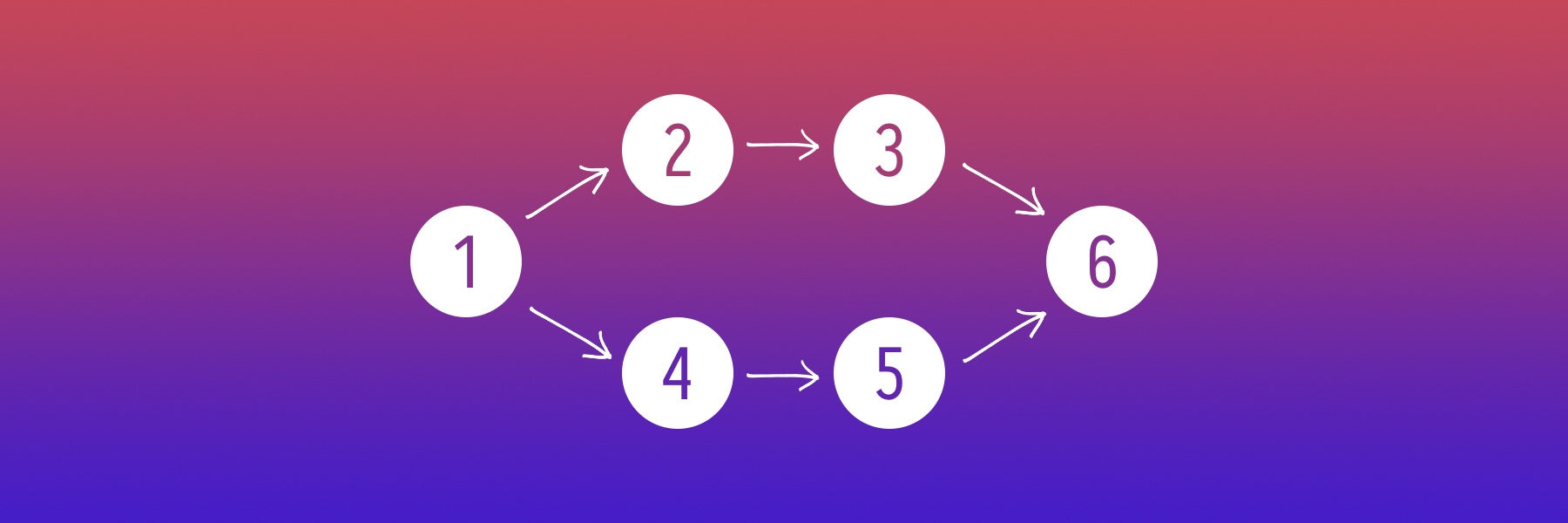
- 1, 2, 3, 4, 5, 6
- 1, 4, 5, 2, 3, 6
- 1, 2, 4, 3, 5, 6
- 1, 2, 4, 5, 3, 6
- 1, 4, 2, 3, 5, 6
- 1, 4, 2, 5, 3, 6
If you add to nodes 2 and 3 node 4 as control dependency that means that node 4 will be executed before node 2 and node 3 and the second or fifth ordering will be used. It can be useful if node 2 or node 3 have side effects which will modify data in node 1 and node 4 needs to receive unmodified data.
When we defined all the nodes we can create a graph defining the function name to be later used to compile the function.
You pass all the nodes to graph’s nodes argument and also you may select one of the node as the output node of the graph and the return type of this node will be used as return type of the graph function. If you don’t provide output node the graph will be compiled as a void function.
Graph attributes is an array of MTLFunctionStitchingAttribute which in iOS17/macOS12 API has only one option MTLFunctionStitchingAttributeAlwaysInline. This option will apply __attribute__((always_inline)) to resulting function.
Readers familiar with Metal pipelines may notice that all these initializers are not throwable or return optional types which is not common for Metal APIs. This is because MTLFunctionStitchingGraph is just a description of the graph and it doesn’t check if the graph is valid. It will be checked during compilation later.
Compiling the Graph
let device = MTLCreateSystemDefaultDevice()!
let library = device.makeDefaultLibrary()!
let functions = [
library.makeFunction(name: "read_color")!,
library.makeFunction(name: "grayscale_color")!,
library.makeFunction(name: "invert_color")!,
library.makeFunction(name: "write_color")!,
]
let stitchedDescriptor = MTLStitchedLibraryDescriptor()
stitchedDescriptor.functions = functions
stitchedDescriptor.functionGraphs = [graph]
let stitchedLibrary = try! device.makeLibrary(stitchedDescriptor: stitchedDescriptor)
let stitchedFunction = stitchedLibrary.makeFunction(name: "process_graph")!Here we perform an actual graph compilation into a single function and you see a lot of force unwraps and tries here :) First we create MTLFunction objects for all our graph’s nodes functions and using a familiar descriptor pattern create a library with a single function which will execute our graph. And finally create an MTLFunction object with the name of our graph function.
If you look at the Apple’s example for stitching graph you’ll see there that next to [[ stitchable ]] functions they declare [[ visible ]] function inside Metal file to which the graph will be stitched. We’ll use it also in next section, but I found that it is not required and you can compile function graph without any declarations inside your precompiled library.
The resulting graph function may look like this:
[[ visible ]]
void process_graph(texture2d<half, access::read> arg1,
texture2d<half, access::write> arg2,
ushort2 arg3) {
const half4 var1 = arg1.read(arg3);
const half4 var2 = half4(half3((var1.r + var1.b + var1.g) / 3.0h), var1.a);
const half4 var3 = half4(half3(1.0h - var2.rgb), var2.a);
arg2.write(var3, arg3);
}This is the main part of our uber-shader which was compiled in runtime using precompiled functions from existing Metal library without any preprocessing macros or function constants. Metal Stitchable API is rather verbose as you see but it can give you more flexibility and control over uber-shader creation.
[[ visible ]] is another MSL function qualifier which is used to mark functions which can be used to create MTLFunction object on CPU side. It is similar to [[ kernel ]] function but it can’t be called directly i.e. assigned to computeFunction in MTLComputePipelineState object.
And here comes a tricky part. How to call this function?
Calling the Graph (Predefined Arguments)
For now we have a hardcoded graph which has three arguments and we know the types of them. If you want to build graphs of this kind where inputs and output are already known you can add a wrapper kernel right inside your Metal library and call it directly. Add this to your Metal file right after [[ stitchable ]] functions:
[[ visible ]]
void process_graph(texture2d<half, access::read> src,
texture2d<half, access::write> dst,
const ushort2 pos);
[[ kernel ]]
void process_graph_kernel(texture2d<half, access::read> src [[ texture(0) ]],
texture2d<half, access::write> dst [[ texture(1) ]],
const ushort2 pos [[ thread_position_in_grid ]]) {
process_graph(src, dst, pos);
}Here we declare a [[ visible ]] function and implementation of it will be compiled during graph creation. And from [[ kernel ]] function with predefined arguments we simply call this function. Here is how to create pipeline state to encode this function.
let linkedFunctions = MTLLinkedFunctions()
linkedFunctions.privateFunctions = [stitchedFunction]
let descriptor = MTLComputePipelineDescriptor()
descriptor.computeFunction = library.makeFunction(name: "process_graph_kernel")!
descriptor.linkedFunctions = linkedFunctions
let pipelineState = try! gpu.device.makeComputePipelineState(descriptor: descriptor, options: []).0And after this you can use this pipeline state in your processing.
The only difference comparing to “usual” kernel encoding in this case is that you need to add your graph function to linked functions of pipeline state so that kernel will be able to find it. Otherwise you will get a runtime error during pipeline state compilation.
With this approach there is no Metal library compilation from source in runtime. You only use precompiled [[ stitchable ]] functions to create a graph with Metal API. But it would be much more flexible if you could create a graph with arbitrary inputs and outputs and then compile it to a single function. Let’s see how to do it.
Calling the Graph (Arbitrary Arguments)
Unfortunately there is no Metal API to build shaders like we build graph function using node objects. So the only option for us is to compile it from source.
This option is vital if you want to build your own library for GPU processing and MPSGraph with its close architecture doesn’t suit your needs. I’ll show only the basics and provide some guidance how to achieve such functionality but won’t show you how to build general purpose node based processing library on top of Metal Stitching API. It is very much depends on your needs and current architecture of your pipeline.
For demonstration purpose we will compile the same kernel from source code which we had in our library with predefined arguments graph. The only difference is that we don’t have declaration of process_graph visible function so we need another way to call our graph from kernel.
Remember that we already have two Metal libraries. The first one is compiled default.metallib which contains only our [[ stitchable ]] functions. And the second one is a stitched library with a single [[ visible ]] function which executes our graph. Let’s add another library with the [[ kernel ]] function created in runtime.
let source = """
#include <metal_stdlib>
using namespace metal;
using graph_function = void (
texture2d<half, access::read>,
texture2d<half, access::write>,
ushort2
);
[[ kernel ]]
void process_graph_kernel(texture2d<half, access::read> src [[ texture(0) ]],
texture2d<half, access::write> dst [[ texture(1) ]],
visible_function_table<graph_function> table [[ buffer(0) ]],
const ushort2 position [[ thread_position_in_grid ]])
{
table[0](src, dst, position);
}
"""
let kernelLibrary = try! device.makeLibrary(source: source, options: nil)You see that here we don’t use [[ visible ]] function declaration and call it from our shader. Instead we use visible_function_table which will contain a pointer to our graph function. This table is some kind of fixed size array of pointers to [[ visible ]] functions. And we need to create this table on CPU side and pass it to our shader.
let linkedFunctions = MTLLinkedFunctions()
linkedFunctions.functions = [stitchedFunction]
let descriptor = MTLComputePipelineDescriptor()
descriptor.computeFunction = kernelLibrary.makeFunction(name: "process_graph_kernel")!
descriptor.linkedFunctions = linkedFunctions
let pipelineState = try! device.makeComputePipelineState(descriptor: descriptor, options: []).0
let tableDescriptor = MTLVisibleFunctionTableDescriptor()
tableDescriptor.functionCount = 1
let table = pipelineState.makeVisibleFunctionTable(descriptor: tableDescriptor)!
let handle = pipelineState.functionHandle(function: stitchedFunction)!
table.setFunction(handle, index: 0)The first part of this code is rather similar to the previous example. The only difference is that we add stitchedFunction to array of functions and not privateFunctions of MTLLinkedFunctions object because private functions can’t be added to visible function table and need to be called directly from shader code.
Then we create a visible function table, obtain a function handle from pipeline state and add it to table. And finally we can encode our pipeline state.
// Assume that we have source and destination textures and command buffer
let encoder = commandBuffer.makeComputeCommandEncoder()!
encoder.setComputePipelineState(pipelineState)
encoder.setTexture(sourceTexture, index: 0)
encoder.setTexture(destinationTexture, index: 1)
encoder.setVisibleFunctionTable(table, bufferIndex: 0)
encoder.dispatchThreads(...)
encoder.endEncoding()Voila!
Notes about Nodes
First of all thank you for taking this journey inside this very specific Metal API with me. If you’re a node engine developer you may be impressed with it like I was and want immediately implement it in your project. But before you start I want to share some thoughts about this API.
To create something like an MPSGraph library which uses stitching graph will be a nontrivial task. In standard node based architecture nodes are independent from the graph itself. All they expose outside are inputs, outputs and parameters. If you’ll try to convert your current architecture to stitching graph you’ll find that nodes has to tell much more information about theirs behavior.
For example if node outputs a texture with different size than input texture at this point you’ll have to split the graph into separate graphs and each one will encode a kernel with different number of GPU threads. So if your pipeline consists of a lot of convolution operations you may end up with a lot of small graphs which will be inefficient to encode comparing to standard precompiled kernels.
Second you need to think how to pass parameters for each node inside a single kernel which contains several nodes processing. With separate encoder for each node you pass only parameters required for this particular node. With general purpose stitching API you need to pass them to GPU all in a single encoder. And since [[ stitchable ]] functions know nothing about the structure of your nodes you need to pass them inside an array of floats for example. And on CPU side you’ll need to encode graph which will be able to take required parameter from array with a proper index.
From my point of view this API is not ready enough to be easily used in arbitrary GPU processing. Though MPSGraph proves that it is an accomplishable task. Nevertheless it is a good option for encoding fixed pipelines with optional steps, so that you can compile the graph with only selected processing steps. For example postprocessing pipeline in game engines. For processing with arbitrary pipeline it would be better to use indirect encoding as for me which I’ll cover in the next articles.
Conclusion
Uber-shaders without branching in most cases will be a better solution in terms of performance but to maintain them is rather a difficult task. Metal provides several technics to write them: function constants, MSL uniform types and now MTLFunctionStitchingGraph. Which one to use depends on your needs and your pipeline architecture. There is no best solution for all cases. But if you want to find one for your particular case I hope this article and further ones about Metal optimizations will help you to make a decision.
If you’re a game developer or app developer and face issues with Metal performance feel free to contact me and I’ll try to help you. Also follow me on Twitter @mtl_doc to be notified about new articles.
Thanks for reading!